神经网络01:FashionMNIST数据集介绍与展示
介绍 FashionMNIST 数据集
FashionMNIST 是一个用于图像分类任务的基准数据集,由 Zalando Research 提供,旨在替代经典的 MNIST 手写数字数据集。该数据集包含 70,000 张 28×28 像素的灰度图像,分为 10 个类别,每个类别代表一种不同的服装或配饰。FashionMNIST 数据集因其多样性和适中的难度,被广泛用于计算机视觉和机器学习领域的研究和教学,尤其是图像分类任务。
数据集的组成
FashionMNIST 数据集由以下两个主要部分组成:
-
训练集:
- 包含 60,000 张图像,用于训练模型。
- 每张图像的尺寸为 28×28 像素,是灰度图像(单通道)。
-
测试集:
- 包含 10,000 张图像,用于评估模型的性能。
- 每张图像的尺寸同样为 28×28 像素,也是灰度图像(单通道)。
数据集的类别
FashionMNIST 数据集的图像被分为以下 10 个类别,每个类别代表一种不同的服装或配饰:
| 标签 | 类别 |
|---|---|
| 0 | T恤/上衣 |
| 1 | 裤子 |
| 2 | 套头衫 |
| 3 | 连衣裙 |
| 4 | 外套 |
| 5 | 凉鞋 |
| 6 | T恤/衬衫 |
| 7 | 运动鞋 |
| 8 | 包 |
| 9 | 踝靴 |
数据集的特点
FashionMNIST 数据集具有以下特点,使其成为图像分类任务的理想选择:
-
多样性:
- 数据集中的图像涵盖了多种服装和配饰,具有较高的多样性。这使得模型能够学习到不同类别之间的显著特征差异。
-
平衡性:
- 每个类别包含相同数量的图像(训练集每个类别 6,000 张,测试集每个类别 1,000 张),确保了数据的平衡性。这种平衡性有助于模型在不同类别之间进行公平的分类。
-
灰度图像:
- 图像是灰度的,每个像素的值范围为 0 到 255。这种简单的图像格式使得数据集易于处理和加载,同时也降低了计算复杂度。
-
适中的难度:
- 与 MNIST 手写数字数据集相比,FashionMNIST 的图像更加复杂,但难度适中。它既不会过于简单,也不会过于困难,适合用于教学和研究。
-
广泛的应用:
- FashionMNIST 数据集被广泛用于图像分类任务的研究,包括但不限于卷积神经网络(
CNN)、循环神经网络(RNN)和传统机器学习算法。它也常用于比较不同算法的性能。
- FashionMNIST 数据集被广泛用于图像分类任务的研究,包括但不限于卷积神经网络(
数据集的用途
FashionMNIST 数据集在计算机视觉和机器学习领域有广泛的应用,主要包括以下方面:
-
图像分类:
- 该数据集主要用于图像分类任务,训练和评估模型对不同服装和配饰的分类能力。
-
算法研究:
- 由于其适中的难度和多样性,FashionMNIST 数据集常用于研究和比较不同机器学习算法的性能,包括深度学习算法和传统机器学习算法。
-
教学和实践:
- FashionMNIST 数据集被广泛用于教学和实践项目,帮助初学者学习如何处理图像数据、构建和训练模型以及评估模型性能。
-
迁移学习:
- 该数据集也常用于迁移学习任务,通过在 FashionMNIST 上预训练模型,然后将其应用于其他更复杂的图像分类任务。
数据集的加载与可视化
接下来,我们将通过代码展示如何使用 PyTorch 和 torchvision 库加载 FashionMNIST 数据集,并对数据进行预处理和可视化。
加载数据集
使用 torchvision.datasets.FashionMNIST 加载数据集,数据集被存储在指定的路径下(root='./data'),并且在加载时应用了一系列的预处理操作,包括调整图像大小(transforms.Resize(size=224))和将图像转换为张量(transforms.ToTensor())。数据集被设置为训练集(train=True),并且在本地不存在数据集时会自动从网络下载(download=True)。
创建数据加载器
使用 torch.utils.data.DataLoader 创建了一个数据加载器,用于在训练过程中逐批次加载数据。数据加载器的批次大小设置为 64(batch_size=64),并且在每个 epoch 开始时会随机打乱数据(shuffle=True)。
获取一个批次的数据
通过遍历数据加载器,获取了第一个批次的数据(b_x 和 b_y),分别表示图像和对应的标签。
数据转换
将批次的图像张量转换为 NumPy 数组,并移除了第1维(通道维),因为 FashionMNIST 数据集中的图像是灰度图像,通道数为1。将批次的标签张量也转换为 NumPy 数组,便于后续处理。
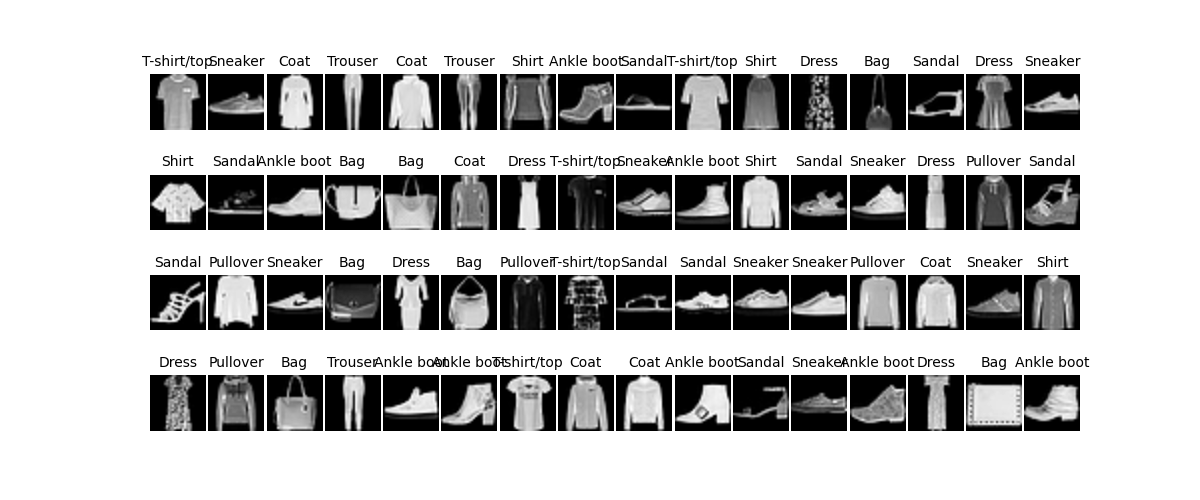
可视化
使用 Matplotlib 库创建了一个图像窗口,显示了一个批次的图像。每个图像都被显示为灰度图,并且图像的类别标签被作为标题显示在每个子图上。通过调整子图之间的间距和关闭坐标轴,使得图像显示更加清晰。
代码及结果展示部分
代码如下:
# 导入必要的库 |
输出结果如下: